2026년, 하네스 엔지니어링이 뜨겁다
요즘 AI 관련 글을 읽다 보면 "하네스 엔지니어링"이라는 말이 빠지질 않는다.
OpenAI는 이 개념을 공식 블로그에서 정의했고, Thoughtworks의 Birgitta Böckeler는 martinfowler.com에 가이드와 센서라는 멘탈 모델을 정리했다. Latent Space에서는 "이게 진짜인가"라는 논쟁이 벌어졌고, 학술 논문까지 나왔다.
DEV Community에서는 다섯 갈래의 정의를 비교하는 글이 올라왔고, Philipp Schmid는 하네스가 곧 데이터셋이라고 주장했으며, InfoSec Today는 "moat는 모델이 아니라 하네스에 있다"는 분석까지 내놨다.
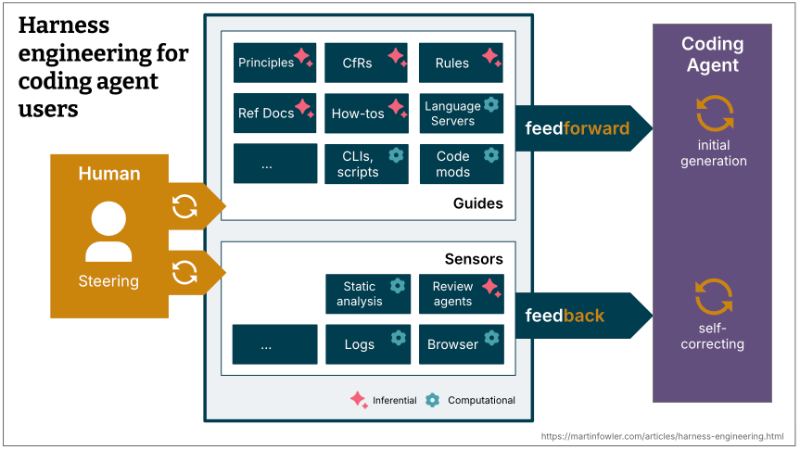
분명 핫한 주제긴 하다. 근데 이 단어가 정말 새로운 뭔가를 가리키는 건지는 좀 따져봐야 한다.
기업들이 원하는 건 결국 하나다
지금 AI를 도입하는 기업들의 목표는 다 같다. 자기 도메인에서 최적의 답변을 내놓는 AI. 법률 회사는 법률에 특화된 AI를, 의료 회사는 의료에 특화된 AI를 원한다. 이건 AI 시대 이전에도 마찬가지였다. 어떤 시스템이든 특정 도메인에 투입하면 그 도메인의 규칙을 가르쳐야 한다.
하네스 엔지니어링이 해결하려는 문제라는 것도 결국 이거다. AI 모델이 우리 도메인의 맥락을 모르니까, 그걸 알려주고, 엉뚱한 답을 못 하게 막는 것.
신입사원 온보딩과 다를 게 없다
아무리 뛰어난 개발자를 뽑아도, 회사에 처음 들어오면 온보딩을 받는다. 코드 컨벤션, 아키텍처 결정 사항, 배포 프로세스, 도메인 용어, 이런 것들은 그 사람이 아무리 실력이 좋아도 알 수 없다. 회사 밖에는 없는 지식이니까.
AI 모델도 마찬가지다. GPT든 Claude든, 모델이 아무리 똑똑해져도 우리 회사의 내부 API 규칙이나 비즈니스 로직을 알 리가 없다. 그래서 프롬프트로 규칙을 알려주고, lint로 스타일을 잡고, 테스트로 동작을 검증한다.
이게 하네스 엔지니어링의 실체다. 새로운 엔지니어링 분야가 아니라, 원래 해야 했던 일이다.
이건 모델 성능 향상이 아니다
여기서 하나 짚고 갈 게 있다. 하네스 엔지니어링은 모델의 성능을 끌어올리는 일이 아니다. 이미 정해진 모델의 능력을 특정 방향으로 유도하는 것이다.
lint가 코드의 품질을 올리는 게 아니라 스타일을 강제하듯, tsc가 프로그래머의 실력을 올리는 게 아니라 타입 안전성을 강제하듯, 하네스는 모델의 출력을 제약할 뿐이다. 모델 자체가 더 똑똑해지는 건 아니다.
OpenAI가 커스텀 린터와 구조 테스트로 아키텍처를 강제하고, 주기적으로 드리프트를 스캔해서 에이전트가 수정을 제안하게 한다는 이야기도 결국 같은 맥락이다. 모델이 더 잘하게 만든 게 아니라, 모델이 잘못하는 걸 덜 잘못하게 만든 것이다.
그런데 이야기가 너무 과열됐다
하네스 엔지니어링을 둘러싼 이야기들에는 불편한 점이 있다.
첫째, 정의조차 합의되지 않았다. DEV Community의 비교 글을 보면, 5개 주체가 5가지 다른 정의를 내리고 있다. OpenAI는 선언적 제약 시스템이라 하고, Anthropic은 context anxiety 해결이라 하고, LangChain은 에이전트란 모델과 하네스의 합이라 하고, Böckeler는 린터나 타입 체커 같은 기존 도구도 하네스라고 하고, 학술 논문은 검증 가능한 명세로 형식화하자고 한다. 무엇이 하네스이고 무엇이 아닌지의 경계조차 불분명한데, 벌써 직군 이름이 되려 하고 있다.
둘째, 숫자가 알맹이보다 앞서간다. LangChain이 하네스만 바꿔서 Terminal Bench 2.0 순위를 30위권에서 5위권으로 끌어올렸다고 밝힌 뒤로, 이 사례가 계속 인용된다. 정리된 수치를 보면 기본 프롬프트와 도구 세팅이 52.8%, 커스텀 프롬프트와 미들웨어에 추론 강도까지 올리면 66.5%다. 모델은 그대로인 채로. 이걸 "하네스 엔지니어링의 성과"라고 부른다. 하지만 실제로 한 일을 보면 시스템 프롬프트를 바꾸고, 빌드-검증 루프를 추가하고, reasoning 레벨을 xhigh로 올린 것이다. 이건 프롬프트 튜닝과 도구 세팅이지, 새로운 엔지니어링 분야의 성과라고 부르기엔 과하다.
셋째, "moat는 하네스에 있다"는 주장은 성급하다. InfoSec Today는 하네스가 모델보다 더 큰 경쟁 우위라고 분석했고, Philipp Schmid는 하네스가 쌓는 실행 기록 자체가 경쟁 우위가 된다고 주장한다. 하지만 프롬프트와 가드레일이 경쟁 우위가 된다는 건, 설정 파일이 기술 장벽이라고 말하는 것과 다를 바 없다. 진짜 경쟁 우위는 그 안에 담기는 도메인 지식이다.
모델이 발전해도 하네스는 사라지지 않는다
Latent Space 논쟁에서 Noam Brown은 "현재 사람들이 만드는 스캐폴딩도 결국 모델이 더 똑똑해지면 대체될 것"이라고 했다. 이른바 Bitter Lesson, 영리한 엔지니어링보다 단순한 스케일링이 길게 보면 더 낫다는 교훈이다.
나는 이 주장에 동의하지 않는다.
모델이 아무리 발전해도, 세상에 없는 지식은 학습할 수 없다. 우리 회사의 내부 코드 컨벤션, 아직 공개되지 않은 API 스펙, 우리 팀만 아는 도메인 규칙, 이런 것들은 인터넷 어디에도 없다. 모델의 파라미터를 10배로 늘려도 모르는 건 모른다.
그래서 하네스는 사라지지 않는다. 다만 그건 "하네스 엔지니어링이 대단한 분야여서"가 아니라, 도메인 지식 전달은 어떤 시스템에든 필요한 기본적인 일이기 때문이다.
결국 AI는 사람에 가까워지고 있다
이 글을 쓰면서 한 가지 생각이 계속 맴돌았다. 하네스 엔지니어링 이야기를 따라가다 보면, 결국 우리가 AI에게 하는 일이 사람에게 하는 일과 점점 닮아가고 있다는 걸 느낀다.
신입사원이 들어오면 온보딩 문서를 읽히고, 코드 컨벤션을 지키게 하고, 시니어가 코드 리뷰를 하고, CI가 테스트를 돌린다. 잘못된 패턴을 쓰면 lint가 잡고, 위험한 코드를 머지하려 하면 리뷰어가 막는다. 이 모든 과정의 목표는 하나다. 이 사람을 우리 도메인에 맞는 사람으로 만드는 것.
하네스 엔지니어링이 하는 일도 정확히 이거다. 프롬프트로 맥락을 주고, 가드레일로 제약을 걸고, 테스트로 검증하고, 잘못되면 재시도시킨다. 대상이 사람에서 모델로 바뀌었을 뿐, 구조는 같다.
인공신경망으로 학습된 모델이 사람의 사고방식에 가까워지고 있다면, 그 모델을 조직에 적응시키는 방법도 사람을 적응시키는 방법과 닮아가는 건 어쩌면 당연하다. 하네스 엔지니어링은 새로운 엔지니어링 분야가 아니라, AI가 충분히 사람과 비슷해졌기 때문에 생긴 자연스러운 현상일 뿐이다.
거창한 이름이 붙었다고 해서 알맹이가 달라지는 건 아니다. 우리는 예전부터 이 일을 해왔다. 대상이 바뀌었을 뿐이다.
참고 자료
- OpenAI, Harness Engineering
- Birgitta Böckeler, Harness engineering for coding agent users
- LangChain, The Anatomy of an Agent Harness
- Philipp Schmid, Agent Harness 2026