최신 문서를 줘도 옛날 코드를 쓰는 AI
Next.js 15 코드를 짜달라고 했다. 응답이 어딘가 미묘하다. getServerSideProps가 있고, pages/ 디렉터리 가정이 깔려 있다. 13까진 맞는 코드인데 15 기준으론 틀린 코드다.
공식 문서를 통째로 컨텍스트에 붙였다. "이 문서를 따라라"라고 명시했다. 답은 살짝 달라진다. 그런데 한두 줄만 따라가다 다시 익숙한 옛날 패턴으로 돌아간다.
이 경험을 한 번이라도 해본 사람이라면, AI 코딩 에이전트의 한계가 단순한 "지식 부족"이 아니란 걸 안다. 모델이 모르는 게 아니다. 알고 있는 걸 못 버리는 거다.
이건 무지가 아니라 충돌이다
학계는 이 현상에 이름을 붙여놨다. Knowledge Conflict.
LLM 안에는 두 종류의 지식이 공존한다. 하나는 가중치에 박혀 있는 parametric knowledge, 학습 데이터가 모델 파라미터에 압축돼 들어간 지식이다. 다른 하나는 contextual knowledge, 추론 시점에 프롬프트로 주어지는 지식이다. RAG, 시스템 프롬프트, 첨부한 문서, 전부 여기 들어간다.
평소엔 둘이 맞물려 돌아간다. 그런데 둘이 충돌하는 순간, 모델은 한쪽을 골라야 한다. 그리고 모델은 자주, 자기가 학습한 쪽을 고른다.
EMNLP 2024 서베이 논문 Knowledge Conflicts for LLMs는 이 충돌을 정식으로 정의하고 분류했다. 학계에서 이걸 별도의 연구 영역으로 다룬다는 사실 자체가, 이 문제가 한두 모델의 결함이 아니라 LLM이라는 아키텍처에 내장된 특성이라는 뜻이다.
명시적으로 지시해도 안 통한다
가장 곤란한 발견은 이거다. 모델에게 명시적으로 "주어진 컨텍스트를 따르고 네 지식을 무시해라"라고 시켜도, 완전히 억누르지 못한다.
Understanding the Interplay between Parametric and Contextual Knowledge는 이 비대칭을 정량적으로 측정했다. 문맥과 내부 지식이 충돌할 때, 모델 성능은 둘이 일치할 때보다 일관되게 떨어진다. 컨텍스트만 따르라고 강하게 지시해도 그렇다. 반대로 "네 지식을 써라"라고 했을 때도, 모델은 이미 컨텍스트가 있으면 그걸 완전히 무시하지 못한다. 어느 한쪽으로도 깔끔하게 정리되지 않는다.
Task Matters라는 후속 연구는 더 정밀하게 들어간다. 충돌의 영향은 작업 종류에 따라 다르다. 지식이 거의 필요 없는 작업(요약, 포맷 변환)에선 컨텍스트를 잘 따른다. 그런데 knowledge-intensive 작업, 그러니까 모델이 많이 학습한 영역에 들어가는 순간, 충돌이 성능을 크게 떨어뜨린다.
코딩이 정확히 이 영역이다. API, 라이브러리 시그니처, 문법, 베스트 프랙티스. 모델이 가장 많이 학습한 영역이고, 그래서 가장 강하게 자기 지식을 신뢰한다.
세 가지 충돌
서베이는 충돌을 세 종류로 나눈다. 셋 다 코딩 에이전트에서 매일 일어난다.
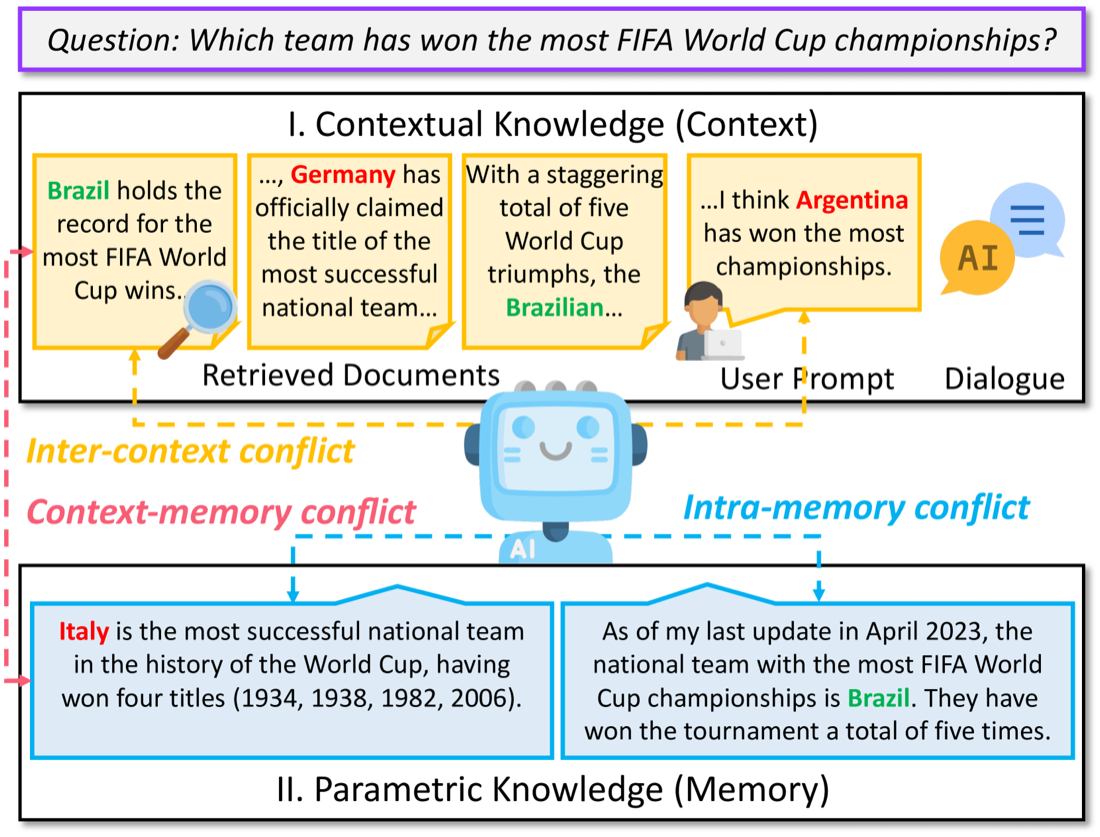
Context-memory conflict. 컨텍스트와 모델 내부 지식이 부딪힌다. 가장 흔한 케이스다. 최신 문서를 붙여줬는데 모델은 학습 시점의 옛날 API로 돌아간다.
Inter-context conflict. 컨텍스트 안의 정보끼리 부딪힌다. README엔 v3 예제가 있는데 코드베이스엔 v2가 깔려 있을 때. 사용자가 붙인 문서 두 개의 버전이 다를 때. 모델은 어느 쪽을 따라야 할지 결정 못 하고, 둘을 어색하게 섞어버린다.
Intra-memory conflict. 모델 내부 지식 자체가 일관되지 않다. 같은 질문을 살짝 다르게 물어보면 다른 답이 나온다. 학습 데이터에 들어 있는 여러 시점, 여러 버전의 정보가 가중치 안에서 단일한 답으로 수렴되지 못한 결과다.
세 충돌이 동시에 일어나면 디버깅이 거의 불가능해진다. 모델이 왜 그 코드를 썼는지 추적할 길이 없다. 사용자 컨텍스트 탓인지, 학습 지식 탓인지, 학습 지식 안의 어느 시점 탓인지.
코딩 에이전트가 가장 크게 타격을 받는다
When LLMs Lag Behind는 코드 생성 영역에서 이 충돌이 어떻게 작동하는지 측정했다. 결론은 단순하다. 라이브러리 API가 진화하면, 모델은 그걸 못 따라간다. 최신 스펙을 프롬프트로 주입해도 마찬가지다. 모델은 자주 stale parametric knowledge로 회귀한다. 업데이트 설명만 줬을 때 실행되는 코드는 평균 42.55%였고, 문서를 통째로 붙여줘도 66.36%까지밖에 오르지 않았다. 스펙을 다 줘도 세 번에 한 번은 실행조차 안 된다는 뜻이다.
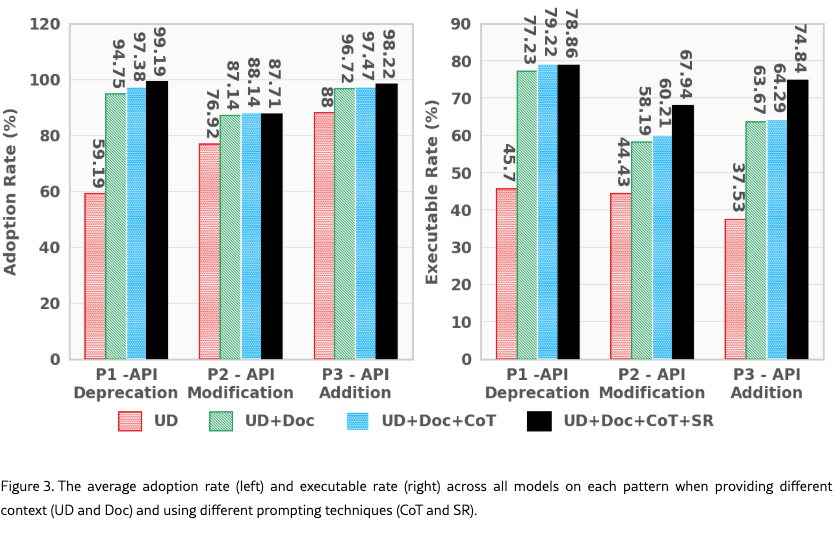
이게 단순한 "knowledge cutoff" 문제가 아니라는 게 핵심이다. 컷오프는 "모르는 것"의 문제고, 이건 "아는 걸 못 버리는 것"의 문제다. 둘은 결이 다르다.
컷오프는 RAG로 푼다. 최신 정보를 컨텍스트에 넣어주면 된다. 그런데 Knowledge Conflict는 RAG로 안 풀린다. 정보를 넣어줘도 모델이 그걸 자기 지식보다 신뢰하지 않으면 그만이다. RAG는 모델이 모를 때만 작동한다. 모델이 "안다고 착각할 때"는 작동하지 않는다.
RAG로는 안 풀린다
지난 2-3년간 LLM 업계는 RAG를 일종의 만능 해결책처럼 다뤘다. 환각이 문제? RAG로 풀어라. 최신성? RAG. 도메인 특화? RAG.
이 낙관에는 전제가 하나 깔려 있었다. 모델은 컨텍스트에 정답이 있으면 그걸 충실히 쓴다는 것.
그런데 Knowledge Conflict 연구가 보여주는 건 그 가정이 부분적으로만 참이라는 거다. 모델이 자기 지식이 없는 영역에서는 RAG가 잘 작동한다. 모르는 사람의 위키피디아 문서를 붙여주면 그걸 충실히 인용한다. 그런데 모델이 강하게 학습한 영역, 코딩처럼 자신감이 높은 영역에선, RAG로 넣어준 정보를 모델의 prior가 부분적으로 무시해버린다.
기업 RAG 시스템의 성능이 데모와 프로덕션에서 자주 갈리는 이유 중 하나가 이거다. 데모는 모델이 모르는 영역(회사 내부 문서)에서 만들어지는데, 실제 사용자는 모델이 강하게 학습한 영역(일반 코딩, 일반 지식)에서 답을 받기 때문이다. 후자에선 모델의 prior가 컨텍스트를 자주 눌러버린다.
그럼 어떻게 해야 하나
이 문제는 "프롬프트를 더 잘 쓰면" 풀리는 문제가 아니다. 모델 아키텍처 차원의 비대칭이고, 현재로선 부분적으로만 완화할 수 있다.
실무에서 할 수 있는 건 이 정도다.
충돌 영역을 의식하고 설계한다. 모델이 강한 영역(주류 라이브러리, 표준 패턴)일수록 컨텍스트 우선이 안 통한다는 걸 전제한다. 핵심 API는 코드 예제로 못 박는다. 설명만 주는 게 아니라, "이 시그니처를 정확히 이렇게 호출해라"라는 구체 예시를 함께 준다. 추상적 지시로는 모델의 prior를 당해내지 못한다.
컨텍스트 안의 충돌을 줄인다. Inter-context conflict는 우리가 통제할 수 있는 영역이다. 버전이 다른 문서를 동시에 넣지 않는다. 코드베이스의 실제 버전과 붙이는 문서의 버전을 일치시킨다. "정답이 어딨는지"를 모델이 추측하지 않게 만든다.
모델이 자기 지식을 쓴 흔적을 검출한다. 생성 결과를 그대로 신뢰하지 않고, 실제로 컨텍스트에 있는 식별자만 등장하는지 검증하는 단계를 둔다. 코딩이라면 타입 체크, 린터, 컴파일이 그 역할을 한다. AI 코딩 에이전트의 진짜 가치는 생성 단계가 아니라 검증 단계에서 나온다.
물론 모델 쪽에서도 변화가 있다. 앞으로 나올 모델들은 instruction following을 더 강하게 훈련받고, 일부 최신 모델들은 이미 컨텍스트 우선 행동을 명시적으로 학습한다. 이게 일관되게 작동하기 시작하면, 우리가 지금 겪는 답답함의 상당 부분이 줄어들 거다. 다만 아직 거기까지 못 왔다.
우리가 만든 모순
LLM은 처음부터 "많이 아는 것"을 목표로 훈련됐다. 데이터를 늘리고, 파라미터를 키우고, 더 많은 사실을 가중치에 박아 넣었다. 모델이 똑똑하다는 말은 곧 "내부에 정보가 많다"는 뜻이었다.
그런데 에이전트 시대로 들어오면서 요구가 뒤집혔다. 우리는 이제 모델이 자기가 아는 걸 일단 내려놓고 지금 주어진 컨텍스트를 따라주길 원한다. 코드베이스의 실제 버전을 따르고, 우리 회사의 실제 문서를 따르고, 우리가 방금 붙인 최신 스펙을 따라야 한다. 모델이 가진 "일반 지식"은 오히려 방해가 된다.
학습 목표와 사용 요구가 어긋났다. 모델은 "많이 아는 것"으로 보상받았고, 우리는 그 모델에게 "필요할 땐 잊어줄 것"을 요청한다. 이 비대칭이 풀리지 않는 한, RAG도 긴 컨텍스트 윈도우도 절반의 답이다.
진짜 병목은 토큰이 아니다. 신뢰 우선순위다. 모델이 자기가 학습한 걸 얼마나 쉽게 내려놓을 수 있느냐. 이걸 훈련 목표 안에 어떻게 집어넣을 것이냐가, 다음 세대 모델의 진짜 차별점이 될 거다.
지금 우리가 "프롬프트 엔지니어링"이라 부르는 작업의 절반은 사실 이 협상이다. 모델의 prior와 우리가 주는 컨텍스트 사이에서 어느 쪽이 이길지를 매번 다시 줄 세우는 일. 이걸 의식하느냐 못 하느냐가, 같은 모델을 쓰면서도 결과가 갈리는 이유다.
참고 자료
- Knowledge Conflicts for LLMs: A Survey (EMNLP 2024)
- Understanding the Interplay between Parametric and Contextual Knowledge for Large Language Models
- Task Matters: Knowledge Requirements Shape LLM Responses to Context-Memory Conflict
- When LLMs Lag Behind: Knowledge Conflicts from Evolving APIs in Code Generation